Core principles
Concise is key
The context window is a public good. Your Skill shares the context window with everything else Claude needs to know, including:- The system prompt
- Conversation history
- Other Skills’ metadata
- Your actual request
- “Does Claude really need this explanation?”
- “Can I assume Claude knows this?”
- “Does this paragraph justify its token cost?”
Set appropriate degrees of freedom
Match the level of specificity to the task’s fragility and variability. High freedom (text-based instructions): Use when:- Multiple approaches are valid
- Decisions depend on context
- Heuristics guide the approach
- A preferred pattern exists
- Some variation is acceptable
- Configuration affects behavior
- Operations are fragile and error-prone
- Consistency is critical
- A specific sequence must be followed
- Narrow bridge with cliffs on both sides: There’s only one safe way forward. Provide specific guardrails and exact instructions (low freedom). Example: database migrations that must run in exact sequence.
- Open field with no hazards: Many paths lead to success. Give general direction and trust Claude to find the best route (high freedom). Example: code reviews where context determines the best approach.
Test with all models you plan to use
Skills act as additions to models, so effectiveness depends on the underlying model. Test your Skill with all the models you plan to use it with. Testing considerations by model:- Claude Haiku (fast, economical): Does the Skill provide enough guidance?
- Claude Sonnet (balanced): Is the Skill clear and efficient?
- Claude Opus (powerful reasoning): Does the Skill avoid over-explaining?
Skill structure
YAML Frontmatter: The SKILL.md frontmatter supports two fields:
name- Human-readable name of the Skill (64 characters maximum)description- One-line description of what the Skill does and when to use it (1024 characters maximum)
Naming conventions
Use consistent naming patterns to make Skills easier to reference and discuss. We recommend using gerund form (verb + -ing) for Skill names, as this clearly describes the activity or capability the Skill provides. Good naming examples (gerund form):- “Processing PDFs”
- “Analyzing spreadsheets”
- “Managing databases”
- “Testing code”
- “Writing documentation”
- Noun phrases: “PDF Processing”, “Spreadsheet Analysis”
- Action-oriented: “Process PDFs”, “Analyze Spreadsheets”
- Vague names: “Helper”, “Utils”, “Tools”
- Overly generic: “Documents”, “Data”, “Files”
- Inconsistent patterns within your skill collection
- Reference Skills in documentation and conversations
- Understand what a Skill does at a glance
- Organize and search through multiple Skills
- Maintain a professional, cohesive skill library
Writing effective descriptions
Thedescription field enables Skill discovery and should include both what the Skill does and when to use it.
Always write in third person. The description is injected into the system prompt, and inconsistent point-of-view can cause discovery problems.
- Good: “Processes Excel files and generates reports”
- Avoid: “I can help you process Excel files”
- Avoid: “You can use this to process Excel files”
Progressive disclosure patterns
SKILL.md serves as an overview that points Claude to detailed materials as needed, like a table of contents in an onboarding guide. For an explanation of how progressive disclosure works, see How Skills work in the overview. Practical guidance:- Keep SKILL.md body under 500 lines for optimal performance
- Split content into separate files when approaching this limit
- Use the patterns below to organize instructions, code, and resources effectively
Visual overview: From simple to complex
A basic Skill starts with just a SKILL.md file containing metadata and instructions: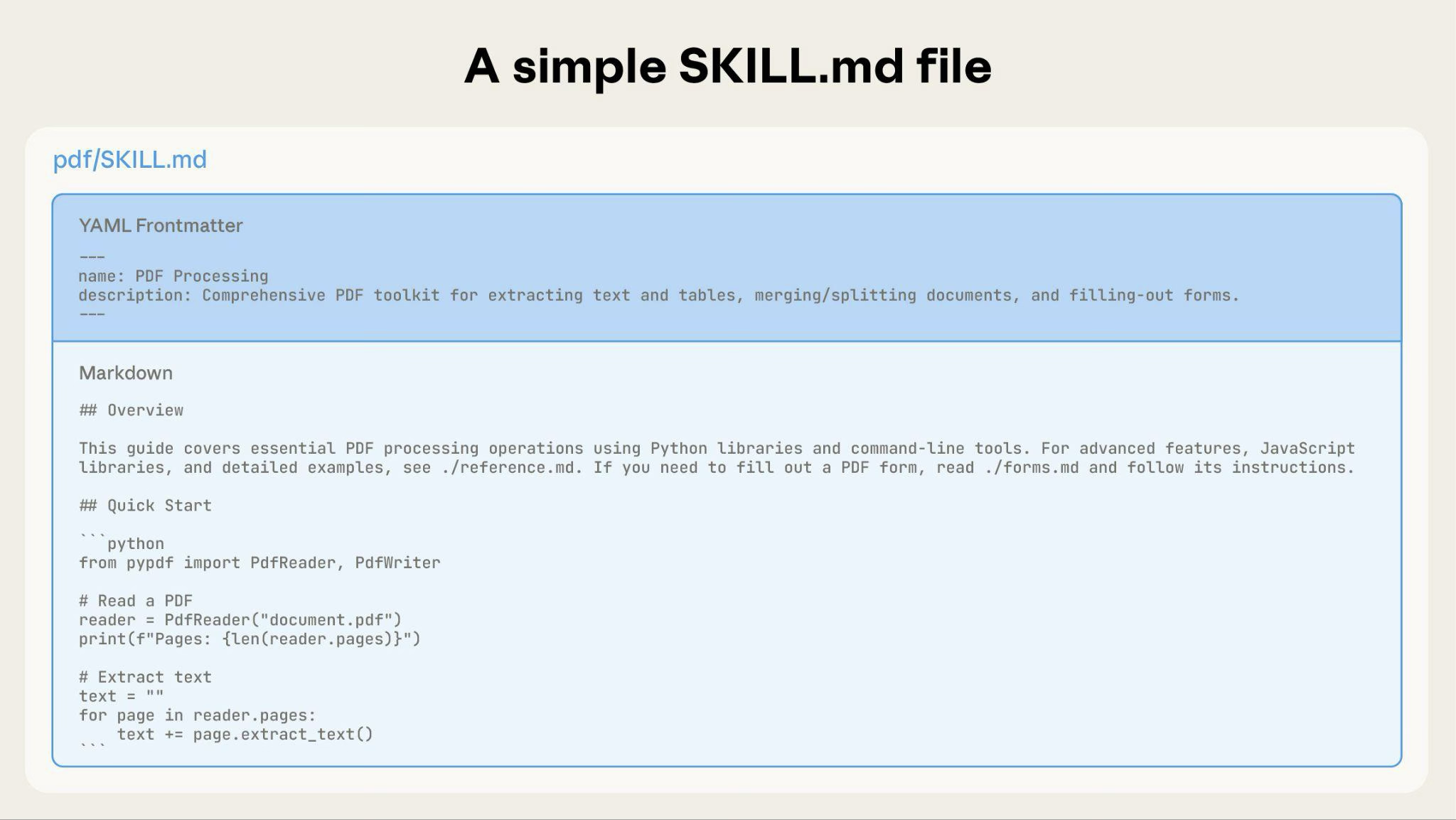

Pattern 1: High-level guide with references
Pattern 2: Domain-specific organization
For Skills with multiple domains, organize content by domain to avoid loading irrelevant context. When a user asks about sales metrics, Claude only needs to read sales-related schemas, not finance or marketing data. This keeps token usage low and context focused.SKILL.md
Pattern 3: Conditional details
Show basic content, link to advanced content:Avoid deeply nested references
Claude may partially read files when they’re referenced from other referenced files. When encountering nested references, Claude might use commands likehead -100 to preview content rather than reading entire files, resulting in incomplete information.
Keep references one level deep from SKILL.md. All reference files should link directly from SKILL.md to ensure Claude reads complete files when needed.
Bad example: Too deep:
Structure longer reference files with table of contents
For reference files longer than 100 lines, include a table of contents at the top. This ensures Claude can see the full scope of available information even when previewing with partial reads. Example:Workflows and feedback loops
Use workflows for complex tasks
Break complex operations into clear, sequential steps. For particularly complex workflows, provide a checklist that Claude can copy into its response and check off as it progresses. Example 1: Research synthesis workflow (for Skills without code):Implement feedback loops
Common pattern: Run validator → fix errors → repeat This pattern greatly improves output quality. Example 1: Style guide compliance (for Skills without code):Content guidelines
Avoid time-sensitive information
Don’t include information that will become outdated: Bad example: Time-sensitive (will become wrong):Use consistent terminology
Choose one term and use it throughout the Skill: Good - Consistent:- Always “API endpoint”
- Always “field”
- Always “extract”
- Mix “API endpoint”, “URL”, “API route”, “path”
- Mix “field”, “box”, “element”, “control”
- Mix “extract”, “pull”, “get”, “retrieve”
Common patterns
Template pattern
Provide templates for output format. Match the level of strictness to your needs. For strict requirements (like API responses or data formats):Examples pattern
For Skills where output quality depends on seeing examples, provide input/output pairs just like in regular prompting:Conditional workflow pattern
Guide Claude through decision points:If workflows become large or complicated with many steps, consider pushing them into separate files and tell Claude to read the appropriate file based on the task at hand.
Evaluation and iteration
Build evaluations first
Create evaluations BEFORE writing extensive documentation. This ensures your Skill solves real problems rather than documenting imagined ones. Evaluation-driven development:- Identify gaps: Run Claude on representative tasks without a Skill. Document specific failures or missing context
- Create evaluations: Build three scenarios that test these gaps
- Establish baseline: Measure Claude’s performance without the Skill
- Write minimal instructions: Create just enough content to address the gaps and pass evaluations
- Iterate: Execute evaluations, compare against baseline, and refine
This example demonstrates a data-driven evaluation with a simple testing rubric. We do not currently provide a built-in way to run these evaluations. Users can create their own evaluation system. Evaluations are your source of truth for measuring Skill effectiveness.
Develop Skills iteratively with Claude
The most effective Skill development process involves Claude itself. Work with one instance of Claude (“Claude A”) to create a Skill that will be used by other instances (“Claude B”). Claude A helps you design and refine instructions, while Claude B tests them in real tasks. This works because Claude models understand both how to write effective agent instructions and what information agents need. Creating a new Skill:- Complete a task without a Skill: Work through a problem with Claude A using normal prompting. As you work, you’ll naturally provide context, explain preferences, and share procedural knowledge. Notice what information you repeatedly provide.
- Identify the reusable pattern: After completing the task, identify what context you provided that would be useful for similar future tasks. Example: If you worked through a BigQuery analysis, you might have provided table names, field definitions, filtering rules (like “always exclude test accounts”), and common query patterns.
-
Ask Claude A to create a Skill: “Create a Skill that captures this BigQuery analysis pattern we just used. Include the table schemas, naming conventions, and the rule about filtering test accounts.”
Claude models understand the Skill format and structure natively. You don’t need special system prompts or a “writing skills” skill to get Claude to help create Skills. Simply ask Claude to create a Skill and it will generate properly structured SKILL.md content with appropriate frontmatter and body content.
- Review for conciseness: Check that Claude A hasn’t added unnecessary explanations. Ask: “Remove the explanation about what win rate means - Claude already knows that.”
- Improve information architecture: Ask Claude A to organize the content more effectively. For example: “Organize this so the table schema is in a separate reference file. We might add more tables later.”
- Test on similar tasks: Use the Skill with Claude B (a fresh instance with the Skill loaded) on related use cases. Observe whether Claude B finds the right information, applies rules correctly, and handles the task successfully.
- Iterate based on observation: If Claude B struggles or misses something, return to Claude A with specifics: “When Claude used this Skill, it forgot to filter by date for Q4. Should we add a section about date filtering patterns?”
- Working with Claude A (the expert who helps refine the Skill)
- Testing with Claude B (the agent using the Skill to perform real work)
- Observing Claude B’s behavior and bringing insights back to Claude A
- Use the Skill in real workflows: Give Claude B (with the Skill loaded) actual tasks, not test scenarios
- Observe Claude B’s behavior: Note where it struggles, succeeds, or makes unexpected choices Example observation: “When I asked Claude B for a regional sales report, it wrote the query but forgot to filter out test accounts, even though the Skill mentions this rule.”
- Return to Claude A for improvements: Share the current SKILL.md and describe what you observed. Ask: “I noticed Claude B forgot to filter test accounts when I asked for a regional report. The Skill mentions filtering, but maybe it’s not prominent enough?”
- Review Claude A’s suggestions: Claude A might suggest reorganizing to make rules more prominent, using stronger language like “MUST filter” instead of “always filter”, or restructuring the workflow section.
- Apply and test changes: Update the Skill with Claude A’s refinements, then test again with Claude B on similar requests
- Repeat based on usage: Continue this observe-refine-test cycle as you encounter new scenarios. Each iteration improves the Skill based on real agent behavior, not assumptions.
- Share Skills with teammates and observe their usage
- Ask: Does the Skill activate when expected? Are instructions clear? What’s missing?
- Incorporate feedback to address blind spots in your own usage patterns
Observe how Claude navigates Skills
As you iterate on Skills, pay attention to how Claude actually uses them in practice. Watch for:- Unexpected exploration paths: Does Claude read files in an order you didn’t anticipate? This might indicate your structure isn’t as intuitive as you thought
- Missed connections: Does Claude fail to follow references to important files? Your links might need to be more explicit or prominent
- Overreliance on certain sections: If Claude repeatedly reads the same file, consider whether that content should be in the main SKILL.md instead
- Ignored content: If Claude never accesses a bundled file, it might be unnecessary or poorly signaled in the main instructions
Anti-patterns to avoid
Avoid Windows-style paths
Always use forward slashes in file paths, even on Windows:- ✓ Good:
scripts/helper.py,reference/guide.md - ✗ Avoid:
scripts\helper.py,reference\guide.md
Avoid offering too many options
Don’t present multiple approaches unless necessary:Advanced: Skills with executable code
The sections below focus on Skills that include executable scripts. If your Skill uses only markdown instructions, skip to Checklist for effective Skills.Solve, don’t punt
When writing scripts for Skills, handle error conditions rather than punting to Claude. Good example: Handle errors explicitly:Provide utility scripts
Even if Claude could write a script, pre-made scripts offer advantages: Benefits of utility scripts:- More reliable than generated code
- Save tokens (no need to include code in context)
- Save time (no code generation required)
- Ensure consistency across uses

- Execute the script (most common): “Run
analyze_form.pyto extract fields” - Read it as reference (for complex logic): “See
analyze_form.pyfor the field extraction algorithm”
Use visual analysis
When inputs can be rendered as images, have Claude analyze them:In this example, you’d need to write the
pdf_to_images.py script.Create verifiable intermediate outputs
When Claude performs complex, open-ended tasks, it can make mistakes. The “plan-validate-execute” pattern catches errors early by having Claude first create a plan in a structured format, then validate that plan with a script before executing it. Example: Imagine asking Claude to update 50 form fields in a PDF based on a spreadsheet. Without validation, Claude might reference non-existent fields, create conflicting values, miss required fields, or apply updates incorrectly. Solution: Use the workflow pattern shown above (PDF form filling), but add an intermediatechanges.json file that gets validated before applying changes. The workflow becomes: analyze → create plan file → validate plan → execute → verify.
Why this pattern works:
- Catches errors early: Validation finds problems before changes are applied
- Machine-verifiable: Scripts provide objective verification
- Reversible planning: Claude can iterate on the plan without touching originals
- Clear debugging: Error messages point to specific problems
Package dependencies
Skills run in the code execution environment with platform-specific limitations:- claude.ai: Can install packages from npm and PyPI and pull from GitHub repositories
- Anthropic API: Has no network access and no runtime package installation
Runtime environment
Skills run in a code execution environment with filesystem access, bash commands, and code execution capabilities. For the conceptual explanation of this architecture, see The Skills architecture in the overview. How this affects your authoring: How Claude accesses Skills:- Metadata pre-loaded: At startup, the name and description from all Skills’ YAML frontmatter are loaded into the system prompt
- Files read on-demand: Claude uses bash Read tools to access SKILL.md and other files from the filesystem when needed
- Scripts executed efficiently: Utility scripts can be executed via bash without loading their full contents into context. Only the script’s output consumes tokens
- No context penalty for large files: Reference files, data, or documentation don’t consume context tokens until actually read
- File paths matter: Claude navigates your skill directory like a filesystem. Use forward slashes (
reference/guide.md), not backslashes - Name files descriptively: Use names that indicate content:
form_validation_rules.md, notdoc2.md - Organize for discovery: Structure directories by domain or feature
- Good:
reference/finance.md,reference/sales.md - Bad:
docs/file1.md,docs/file2.md
- Good:
- Bundle comprehensive resources: Include complete API docs, extensive examples, large datasets; no context penalty until accessed
- Prefer scripts for deterministic operations: Write
validate_form.pyrather than asking Claude to generate validation code - Make execution intent clear:
- “Run
analyze_form.pyto extract fields” (execute) - “See
analyze_form.pyfor the extraction algorithm” (read as reference)
- “Run
- Test file access patterns: Verify Claude can navigate your directory structure by testing with real requests
reference/finance.md, and invokes bash to read just that file. The sales.md and product.md files remain on the filesystem, consuming zero context tokens until needed. This filesystem-based model is what enables progressive disclosure. Claude can navigate and selectively load exactly what each task requires.
For complete details on the technical architecture, see How Skills work in the Skills overview.
MCP tool references
If your Skill uses MCP (Model Context Protocol) tools, always use fully qualified tool names to avoid “tool not found” errors. Format:ServerName:tool_name
Example:
BigQueryandGitHubare MCP server namesbigquery_schemaandcreate_issueare the tool names within those servers
Avoid assuming tools are installed
Don’t assume packages are available:Technical notes
YAML frontmatter requirements
The SKILL.md frontmatter includes onlyname (64 characters max) and description (1024 characters max) fields. See the Skills overview for complete structure details.
Token budgets
Keep SKILL.md body under 500 lines for optimal performance. If your content exceeds this, split it into separate files using the progressive disclosure patterns described earlier. For architectural details, see the Skills overview.Checklist for effective Skills
Before sharing a Skill, verify:Core quality
- Description is specific and includes key terms
- Description includes both what the Skill does and when to use it
- SKILL.md body is under 500 lines
- Additional details are in separate files (if needed)
- No time-sensitive information (or in “old patterns” section)
- Consistent terminology throughout
- Examples are concrete, not abstract
- File references are one level deep
- Progressive disclosure used appropriately
- Workflows have clear steps
Code and scripts
- Scripts solve problems rather than punt to Claude
- Error handling is explicit and helpful
- No “voodoo constants” (all values justified)
- Required packages listed in instructions and verified as available
- Scripts have clear documentation
- No Windows-style paths (all forward slashes)
- Validation/verification steps for critical operations
- Feedback loops included for quality-critical tasks
Testing
- At least three evaluations created
- Tested with Haiku, Sonnet, and Opus
- Tested with real usage scenarios
- Team feedback incorporated (if applicable)