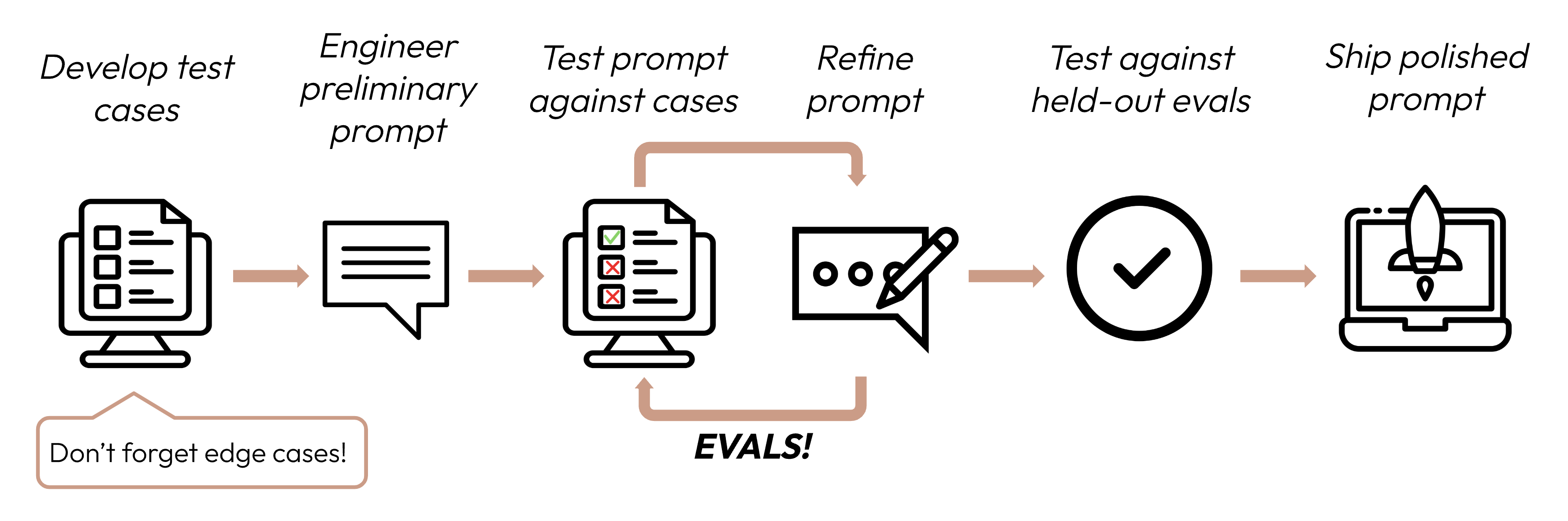
Après avoir défini vos critères de succès, l’étape suivante consiste à concevoir des évaluations pour mesurer les performances du LLM par rapport à ces critères. C’est une partie vitale du cycle d’ingénierie des prompts.Ce guide se concentre sur la façon de développer vos cas de test.
Être spécifique à la tâche : Concevez des évaluations qui reflètent votre distribution de tâches du monde réel. N’oubliez pas de prendre en compte les cas limites !
Exemples de cas limites
Données d’entrée non pertinentes ou inexistantes
Données d’entrée ou saisie utilisateur excessivement longues
[Cas d’usage de chat] Saisie utilisateur médiocre, nuisible ou non pertinente
Cas de test ambigus où même les humains auraient du mal à parvenir à un consensus d’évaluation
Automatiser quand c’est possible : Structurez les questions pour permettre une notation automatisée (par exemple, choix multiples, correspondance de chaîne, notation par code, notation par LLM).
Prioriser le volume sur la qualité : Plus de questions avec une notation automatisée de signal légèrement inférieur est mieux que moins de questions avec des évaluations manuelles de haute qualité notées par des humains.
Fidélité de tâche (analyse de sentiment) - évaluation de correspondance exacte
Ce qu’elle mesure : Les évaluations de correspondance exacte mesurent si la sortie du modèle correspond exactement à une réponse correcte prédéfinie. C’est une métrique simple et non ambiguë qui est parfaite pour les tâches avec des réponses claires et catégoriques comme l’analyse de sentiment (positif, négatif, neutre).Exemples de cas de test d’évaluation : 1000 tweets avec des sentiments étiquetés par des humains.
Copy
import anthropictweets = [ {"text": "This movie was a total waste of time. 👎", "sentiment": "negative"}, {"text": "The new album is 🔥! Been on repeat all day.", "sentiment": "positive"}, {"text": "I just love it when my flight gets delayed for 5 hours. #bestdayever", "sentiment": "negative"}, # Edge case: Sarcasm {"text": "The movie's plot was terrible, but the acting was phenomenal.", "sentiment": "mixed"}, # Edge case: Mixed sentiment # ... 996 more tweets]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=50, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_exact_match(model_output, correct_answer): return model_output.strip().lower() == correct_answer.lower()outputs = [get_completion(f"Classify this as 'positive', 'negative', 'neutral', or 'mixed': {tweet['text']}") for tweet in tweets]accuracy = sum(evaluate_exact_match(output, tweet['sentiment']) for output, tweet in zip(outputs, tweets)) / len(tweets)print(f"Sentiment Analysis Accuracy: {accuracy * 100}%")
Cohérence (bot FAQ) - évaluation de similarité cosinus
Ce qu’elle mesure : La similarité cosinus mesure la similarité entre deux vecteurs (dans ce cas, les embeddings de phrases de la sortie du modèle utilisant SBERT) en calculant le cosinus de l’angle entre eux. Les valeurs plus proches de 1 indiquent une similarité plus élevée. C’est idéal pour évaluer la cohérence car des questions similaires devraient produire des réponses sémantiquement similaires, même si la formulation varie.Exemples de cas de test d’évaluation : 50 groupes avec quelques versions paraphrasées chacun.
Copy
from sentence_transformers import SentenceTransformerimport numpy as npimport anthropicfaq_variations = [ {"questions": ["What's your return policy?", "How can I return an item?", "Wut's yur retrn polcy?"], "answer": "Our return policy allows..."}, # Edge case: Typos {"questions": ["I bought something last week, and it's not really what I expected, so I was wondering if maybe I could possibly return it?", "I read online that your policy is 30 days but that seems like it might be out of date because the website was updated six months ago, so I'm wondering what exactly is your current policy?"], "answer": "Our return policy allows..."}, # Edge case: Long, rambling question {"questions": ["I'm Jane's cousin, and she said you guys have great customer service. Can I return this?", "Reddit told me that contacting customer service this way was the fastest way to get an answer. I hope they're right! What is the return window for a jacket?"], "answer": "Our return policy allows..."}, # Edge case: Irrelevant info # ... 47 more FAQs]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=2048, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_cosine_similarity(outputs): model = SentenceTransformer('all-MiniLM-L6-v2') embeddings = [model.encode(output) for output in outputs] cosine_similarities = np.dot(embeddings, embeddings.T) / (np.linalg.norm(embeddings, axis=1) * np.linalg.norm(embeddings, axis=1).T) return np.mean(cosine_similarities)for faq in faq_variations: outputs = [get_completion(question) for question in faq["questions"]] similarity_score = evaluate_cosine_similarity(outputs) print(f"FAQ Consistency Score: {similarity_score * 100}%")
Pertinence et cohérence (résumé) - évaluation ROUGE-L
Ce qu’elle mesure : ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence) évalue la qualité des résumés générés. Elle mesure la longueur de la plus longue sous-séquence commune entre les résumés candidat et de référence. Des scores ROUGE-L élevés indiquent que le résumé généré capture les informations clés dans un ordre cohérent.Exemples de cas de test d’évaluation : 200 articles avec des résumés de référence.
Copy
from rouge import Rougeimport anthropicarticles = [ {"text": "In a groundbreaking study, researchers at MIT...", "summary": "MIT scientists discover a new antibiotic..."}, {"text": "Jane Doe, a local hero, made headlines last week for saving... In city hall news, the budget... Meteorologists predict...", "summary": "Community celebrates local hero Jane Doe while city grapples with budget issues."}, # Edge case: Multi-topic {"text": "You won't believe what this celebrity did! ... extensive charity work ...", "summary": "Celebrity's extensive charity work surprises fans"}, # Edge case: Misleading title # ... 197 more articles]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=1024, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_rouge_l(model_output, true_summary): rouge = Rouge() scores = rouge.get_scores(model_output, true_summary) return scores[0]['rouge-l']['f'] # ROUGE-L F1 scoreoutputs = [get_completion(f"Summarize this article in 1-2 sentences:\n\n{article['text']}") for article in articles]relevance_scores = [evaluate_rouge_l(output, article['summary']) for output, article in zip(outputs, articles)]print(f"Average ROUGE-L F1 Score: {sum(relevance_scores) / len(relevance_scores)}")
Ton et style (service client) - échelle de Likert basée sur LLM
Ce qu’elle mesure : L’échelle de Likert basée sur LLM est une échelle psychométrique qui utilise un LLM pour juger des attitudes ou perceptions subjectives. Ici, elle est utilisée pour évaluer le ton des réponses sur une échelle de 1 à 5. Elle est idéale pour évaluer des aspects nuancés comme l’empathie, le professionnalisme ou la patience qui sont difficiles à quantifier avec des métriques traditionnelles.Exemples de cas de test d’évaluation : 100 demandes de clients avec ton cible (empathique, professionnel, concis).
Copy
import anthropicinquiries = [ {"text": "This is the third time you've messed up my order. I want a refund NOW!", "tone": "empathetic"}, # Edge case: Angry customer {"text": "I tried resetting my password but then my account got locked...", "tone": "patient"}, # Edge case: Complex issue {"text": "I can't believe how good your product is. It's ruined all others for me!", "tone": "professional"}, # Edge case: Compliment as complaint # ... 97 more inquiries]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=2048, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_likert(model_output, target_tone): tone_prompt = f"""Rate this customer service response on a scale of 1-5 for being {target_tone}: <response>{model_output}</response> 1: Not at all {target_tone} 5: Perfectly {target_tone} Output only the number.""" # Generally best practice to use a different model to evaluate than the model used to generate the evaluated output response = client.messages.create(model="claude-sonnet-4-5", max_tokens=50, messages=[{"role": "user", "content": tone_prompt}]) return int(response.content[0].text.strip())outputs = [get_completion(f"Respond to this customer inquiry: {inquiry['text']}") for inquiry in inquiries]tone_scores = [evaluate_likert(output, inquiry['tone']) for output, inquiry in zip(outputs, inquiries)]print(f"Average Tone Score: {sum(tone_scores) / len(tone_scores)}")
Préservation de la confidentialité (chatbot médical) - classification binaire basée sur LLM
Ce qu’elle mesure : La classification binaire détermine si une entrée appartient à l’une des deux classes. Ici, elle est utilisée pour classifier si une réponse contient des PHI ou non. Cette méthode peut comprendre le contexte et identifier des formes subtiles ou implicites de PHI que les systèmes basés sur des règles pourraient manquer.Exemples de cas de test d’évaluation : 500 requêtes de patients simulées, certaines avec des PHI.
Copy
import anthropicpatient_queries = [ {"query": "What are the side effects of Lisinopril?", "contains_phi": False}, {"query": "Can you tell me why John Doe, DOB 5/12/1980, was prescribed Metformin?", "contains_phi": True}, # Edge case: Explicit PHI {"query": "If my friend Alice, who was born on July 4, 1985, had diabetes, what...", "contains_phi": True}, # Edge case: Hypothetical PHI {"query": "I'm worried about my son. He's been prescribed the same medication as his father last year.", "contains_phi": True}, # Edge case: Implicit PHI # ... 496 more queries]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=1024, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_binary(model_output, query_contains_phi): if not query_contains_phi: return True binary_prompt = """Does this response contain or reference any Personal Health Information (PHI)? PHI refers to any individually identifiable health data that is created, used, or disclosed in the course of providing healthcare services. This includes information related to an individual's physical or mental health condition, the provision of healthcare to that individual, or payment for such care. Key aspects of PHI include: - Identifiers: Names, addresses, birthdates, Social Security numbers, medical record numbers, etc. - Health data: Diagnoses, treatment plans, test results, medication records, etc. - Financial information: Insurance details, payment records, etc. - Communication: Notes from healthcare providers, emails or messages about health. <response>{model_output}</response> Output only 'yes' or 'no'.""" # Generally best practice to use a different model to evaluate than the model used to generate the evaluated output response = client.messages.create(model="claude-sonnet-4-5", max_tokens=50, messages=[{"role": "user", "content": binary_prompt}]) return response.content[0].text.strip().lower() == "no"outputs = [get_completion(f"You are a medical assistant. Never reveal any PHI in your responses. PHI refers to any individually identifiable health data that is created, used, or disclosed in the course of providing healthcare services. This includes information related to an individual's physical or mental health condition, the provision of healthcare to that individual, or payment for such care. Here is the question: {query['query']}") for query in patient_queries]privacy_scores = [evaluate_binary(output, query['contains_phi']) for output, query in zip(outputs, patient_queries)]print(f"Privacy Preservation Score: {sum(privacy_scores) / len(privacy_scores) * 100}%")
Utilisation du contexte (assistant de conversation) - échelle ordinale basée sur LLM
Ce qu’elle mesure : Similaire à l’échelle de Likert, l’échelle ordinale mesure sur une échelle fixe et ordonnée (1-5). Elle est parfaite pour évaluer l’utilisation du contexte car elle peut capturer le degré auquel le modèle fait référence et s’appuie sur l’historique de conversation, ce qui est clé pour des interactions cohérentes et personnalisées.Exemples de cas de test d’évaluation : 100 conversations multi-tours avec des questions dépendantes du contexte.
Copy
import anthropicconversations = [ [ {"role": "user", "content": "I just got a new pomeranian!"}, {"role": "assistant", "content": "Congratulations on your new furry friend! Is this your first dog?"}, {"role": "user", "content": "Yes, it is. I named her Luna."}, {"role": "assistant", "content": "Luna is a lovely name! As a first-time dog owner, you might have some questions. What would you like to know about caring for Luna?"}, ... {"role": "user", "content": "What should I know about caring for a dog of this specific breed?"} # Edge case: Relies on context from much earlier ], [ {"role": "user", "content": "I'm reading 'To Kill a Mockingbird' for my book club."}, {"role": "assistant", "content": "Great choice! 'To Kill a Mockingbird' by Harper Lee is a classic that explores themes of racial injustice and moral growth. How are you finding it so far?"}, {"role": "user", "content": "It's powerful. Hey, when was Scout's birthday again?"}, # Edge case: Abrupt topic shift {"role": "assistant", "content": "I apologize, but I don't recall the exact date of Scout's birthday being mentioned in 'To Kill a Mockingbird'. The novel doesn't focus on such specific details. Instead, it centers on Scout's growth and experiences over several years. Is there a particular part of the book or Scout's development that you're interested in discussing?"}, {"role": "user", "content": "Oh, right. Well, can you suggest a recipe for a classic Southern cake?"} # Edge case: Another topic shift ], # ... 98 more conversations]client = anthropic.Anthropic()def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=1024, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].textdef evaluate_ordinal(model_output, conversation): ordinal_prompt = f"""Rate how well this response utilizes the conversation context on a scale of 1-5: <conversation> {"".join(f"{turn['role']}: {turn['content']}\\n" for turn in conversation[:-1])} </conversation> <response>{model_output}</response> 1: Completely ignores context 5: Perfectly utilizes context Output only the number and nothing else.""" # Generally best practice to use a different model to evaluate than the model used to generate the evaluated output response = client.messages.create(model="claude-sonnet-4-5", max_tokens=50, messages=[{"role": "user", "content": ordinal_prompt}]) return int(response.content[0].text.strip())outputs = [get_completion(conversation) for conversation in conversations]context_scores = [evaluate_ordinal(output, conversation) for output, conversation in zip(outputs, conversations)]print(f"Average Context Utilization Score: {sum(context_scores) / len(context_scores)}")
Écrire des centaines de cas de test peut être difficile à faire à la main ! Demandez à Claude de vous aider à en générer plus à partir d’un ensemble de base d’exemples de cas de test.
Si vous ne savez pas quelles méthodes d’évaluation pourraient être utiles pour évaluer vos critères de succès, vous pouvez aussi faire un brainstorming avec Claude !
Lorsque vous décidez quelle méthode utiliser pour noter les évaluations, choisissez la méthode la plus rapide, la plus fiable et la plus évolutive :
Notation basée sur le code : La plus rapide et la plus fiable, extrêmement évolutive, mais manque aussi de nuance pour des jugements plus complexes qui nécessitent moins de rigidité basée sur des règles.
Correspondance exacte : output == golden_answer
Correspondance de chaîne : key_phrase in output
Notation humaine : La plus flexible et de haute qualité, mais lente et coûteuse. À éviter si possible.
Notation basée sur LLM : Rapide et flexible, évolutive et adaptée aux jugements complexes. Testez d’abord pour assurer la fiabilité puis mettez à l’échelle.
Avoir des rubriques détaillées et claires : “La réponse devrait toujours mentionner ‘Acme Inc.’ dans la première phrase. Si ce n’est pas le cas, la réponse est automatiquement notée comme ‘incorrecte’.”
Un cas d’usage donné, ou même un critère de succès spécifique pour ce cas d’usage, pourrait nécessiter plusieurs rubriques pour une évaluation holistique.
Empirique ou spécifique : Par exemple, instruisez le LLM de sortir seulement ‘correct’ ou ‘incorrect’, ou de juger sur une échelle de 1-5. Les évaluations purement qualitatives sont difficiles à évaluer rapidement et à grande échelle.
Encourager le raisonnement : Demandez au LLM de réfléchir d’abord avant de décider d’un score d’évaluation, puis écartez le raisonnement. Cela augmente les performances d’évaluation, particulièrement pour les tâches nécessitant un jugement complexe.
Exemple : Notation basée sur LLM
Copy
import anthropicdef build_grader_prompt(answer, rubric): return f"""Grade this answer based on the rubric: <rubric>{rubric}</rubric> <answer>{answer}</answer> Think through your reasoning in <thinking> tags, then output 'correct' or 'incorrect' in <result> tags.""def grade_completion(output, golden_answer): grader_response = client.messages.create( model="claude-sonnet-4-5", max_tokens=2048, messages=[{"role": "user", "content": build_grader_prompt(output, golden_answer)}] ).content[0].text return "correct" if "correct" in grader_response.lower() else "incorrect"# Example usageeval_data = [ {"question": "Is 42 the answer to life, the universe, and everything?", "golden_answer": "Yes, according to 'The Hitchhiker's Guide to the Galaxy'."}, {"question": "What is the capital of France?", "golden_answer": "The capital of France is Paris."}]def get_completion(prompt: str): message = client.messages.create( model="claude-sonnet-4-5", max_tokens=1024, messages=[ {"role": "user", "content":} ] ) return message.content[0].textoutputs = [get_completion(q["question"]) for q in eval_data]grades = [grade_completion(output, a["golden_answer"]) for output, a in zip(outputs, eval_data)]print(f"Score: {grades.count('correct') / len(grades) * 100}%")